class: center, middle, inverse, title-slide .title[ # Econometría (II / Práctica) ] .subtitle[ ## Magíster en Economía</br>Tema 5: Variables Instrumentales (IV) ] .author[ ### Prof. Luis Chancí ] .date[ ### <a href="http://www.luischanci.com">www.luischanci.com</a> ] --- layout:true <div style="position:absolute; left:60px; bottom:11px; font-size: 10pt; color:#DDDDDD;">Prof. Luis Chancí - Econometría (II / Práctica)</div> --- # Introduction - Endogeneity Endogeneity means that an explanatory variable in a regression model is correlated with the residual or error term. This gives biased and inconsistent parameter estimates (e.g., by OLS), weakening any causal inference conclusion drawn from an empirical model.</br> ## <center>Using DAGs </center> .center[ ] </br></br> Note: Directed Acyclic Graphs are effective in illustrating relationships between variables (particularly, the presence of endogeneity) --- # Introduction - Endogeneity (cont.) Main sources: 1. **Omitted Variable Bias**</br> When one fail to include one or more relevant variables that influence both `\(Y\)` and `\(X\)`. For instance, the true model is `\(Y=X_1\beta_1+X_2\beta_2+u_T\)`, where `\(\mathbb{E}(u_T|X_1,X_2)=0\)`, and the estimated model is `\(Y=X_1\beta_1+u_E\)`. Therefore, `$$\mathbb{E}_X(\hat{\beta}_1)=\beta_1+(X_1'X_1)^{-1}(X_1'X_2)\beta_2\hspace{0.5cm}\text{or for one regresor,}\hspace{0.5cm} \mathbb{E}(\hat{\beta}_{1}|X)\equiv\beta_1+\beta_2\frac{Cov(X_1,\text{Omitted variable})}{Var(X_1)}$$` 2. **Simultaneity or Reverse Causality**</br> When causality runs in both directions between `\(Y\)` and `\(X\)`). Example: Supply-Demand model, `\(Q^d=Q(P)\)` and `\(P=P(Q^d)\)`. 3. **Measurement Error** </br> When `\(X\)` is measured with error (that correlates with the true value of the variable), and this error becomes part of the residual term. 4. **Sample Selection Bias** </br> When the sample is not randomly selected from the population and the process of selection is related to the variables of interest. 5. **Dynamic Panel Bias** </br> When lagged dependent variables are used as regressors and can be correlated with past error terms. --- # Introduction - Endogeneity (cont.) Common approaches to address endogeneity are: - **Control for Additional Variables**</br> Including additional relevant variables in the model to mitigate omitted variable bias. - **Instrumental Variable (IV)**</br> Using instruments that are correlated with the endogenous explanatory variables but uncorrelated with the error term. - **Panel Data Techniques** </br> Utilizing panel data methods that can account for unobserved heterogeneity and dynamic effects. - **Structural Modeling** </br> Building a more comprehensive model that explicitly incorporates the mechanisms causing simultaneity or selection bias. </br> In this section, we review **Instrumental Variable**. --- class: inverse, middle, mline, center # Instrumental Variables (IV) --- # IV - Introduction Instrumental Variables (IV) is a technique aimed at estimating causal relationships when controlled experiments are not feasible but there is an alternative source of information (an alternative source of exogenous variation). For instance, assessing the impact of a having master's degree on wage using a randomized control trial (RCT) is not feasible. There is no a random assignment or random placement in treatment (master's degree). Therefore, an estimate of `\(\beta_1\)` by OLS raises a problem of endogeneity `$$\mathbb{E}[log(wage_i)|School_i,\, Exper_i]=\beta_0 + \beta_1Schooling_i+\beta_2Experience_i$$` <br> In the paper **Instrumental variables and the search for identification: From supply and demand to natural experiments** (_Journal of Economic perspectives_ , 2001) Angrist and Krueger state that the IV method first laid out in Wright (1982) who approached a simultaneous equation identification challenge by using **''variables that appear in one equation to shift this equation and trace out the other''**. Thus, according to this view, instruments are variables that do the **shifting**. --- # IV - Introduction More formally, IV is a method to estimate causal effects by using variables that influence the treatment but are not directly related to the outcome. .center[ 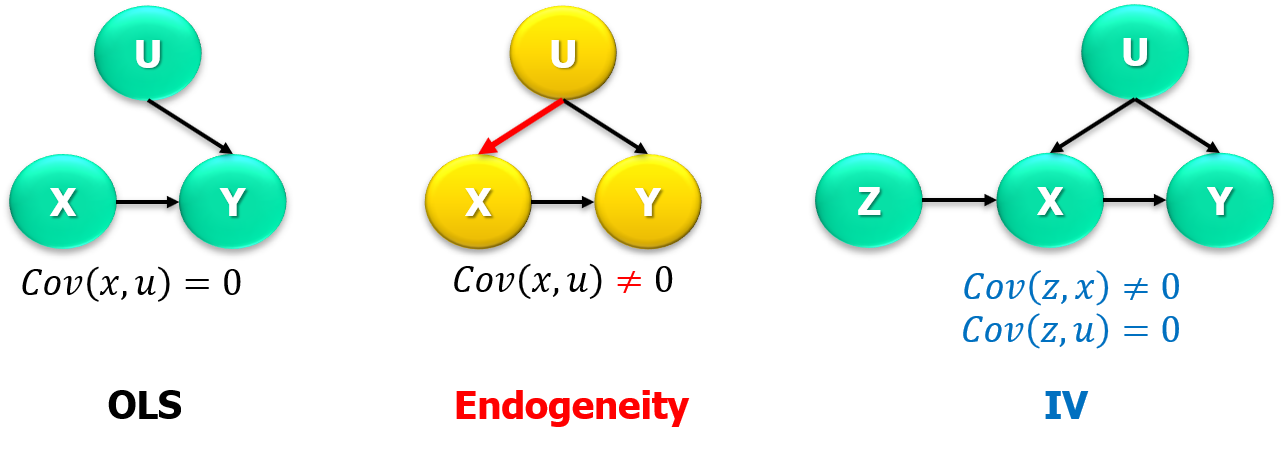] - The interpretation of IV estimates requires careful consideration of the instrument's validity and the assumptions underlying the IV approach. - IV estimates are often interpreted as local average treatment effects (LATE), providing causal inference in a specific subset of the population. --- # IV - conditions and examples A suitable instrument ( `\(z\)` ) for IV must satisfy: 1. **Relevance ( `\(z\rightarrow x\)` ).** The instrument must be correlated with the endogenous explanatory variable, `\(Cor(z,x)\neq0\)`.</br> **Exlusion ( `\(z\rightarrow x \rightarrow y\)` , `\(z\rightarrow/y\)` ):** `\(Cor(z,y|x)=0\)` . 2. **Exogeneity ( `\(u\rightarrow/z\)` ).** The instrument should not be correlated with the error term in the regression model, `\(Cor(z,u)=0\)` . </br></br> Hall of fame - examples of studies using IV: - **David Card's paper (1995) on Education and Earnings**</br> geographical variation in colleges' proximity as an instrument to analyze the return to education. The proximity to a college increases the likelihood of higher education, leading to higher earnings. - **Angrist's paper (1990) on the effects of compulsory military service on earnings** </br> used the Vietnam War draft lottery numbers as an instrument to evaluate the impact of military service on lifetime earnings. --- # Finding instruments A note about finding instruments. - In some studies, finding a source of exogeneous variation could be straightforward. There is a policy or a similar source of variation. - In other cases, the researcher needs to construct more complex (perhaps 'creative') sources of variation. Some examples are: - **Shift-share or Bartik type** instruments associated with T. Bartik (1991). See, Goldsmith-Pinkham, Sorkin, and Swift (2020) - **Simulated instruments** (Borusyak and Hull, 2022) - **Granular instruments** (Gabaix and Koijen, 2023). --- # Finding instruments: Bartik or Shift-Share Instruments The 'Shift-Share' is an useful approach to identify causal relationships where local economic conditions are influenced by broader national or global trends. It is a combination of local industry shares (the shares) with national trends (the shift) to create instruments. The idea is to exploit external/exogenous variation (i.e., national industry trends) that affects the local economy. For instance, considering industries (indexed by `\(k\)`), in geographic locations `\(\ell\)` at time `\(t\)`, a general representation would be like: `$$Z_{\ell,t}=\sum_k (\text{Share}_{\ell,ind,t}\times \text{National Trend}_{k,t})$$` In Autor, Dorn, and Hanson (2013): - They interact local industry shares (in location `\(\ell\)` ) with aggregate trade flows (the growth of imports from China to other high-income countries) to examine the impact of Chinese imports on labor markets in the US. - Thus, the exposure of a location to Chinese imports is a weighted average of how much China is exporting in general of different products ("shift"). The weights are the initial industry composition in a location ("shares"). --- # Instrumental Variables Estimator **Simplest case: Just-identified IV.** One regressor ( `\(k=1\)` ), `\(x\)`, and one instrument ( `\(r=1\)` ), `\(z\)`. Employing `\(Cov(z,u)=0\)`, `$$\begin{eqnarray*} y&=&\beta_1x+u \\ Cov(z,y)&=&Cov(z,\beta_0)+\beta_1Cov(z,x)+Cov(z,u)\\ &=&0+\beta_1Cov(z,x)+0 \\ &=&\beta_1Cov(z,x) \end{eqnarray*}$$` therefore, `$$\hat{\beta}_{IV}=\frac{\sum(z_i-\bar{z})(y_i-\bar{y})}{\sum(z_i-\bar{z})(x_i-\bar{x})}$$` </br> alternatively, we can obtain a similar result using the (Method of) Moments `\(\mathbb{E}(z_iu_i)=0\)` (a technique we will review in the following section). For ease of exposition, let's assume that `\(\bar{z}=0\)`, thus </br> `$$N^{-1}\sum_i{z_i\hat{u}_i}=0 \hspace{0.3cm}\rightarrow\hspace{0.3cm} \sum z_iy_i-\left(\sum z_ix_i\right)\hat{\beta}_{MM}=0 \hspace{0.3cm}\rightarrow\hspace{0.3cm} \hat{\beta}_{MM}=\hat{\beta}_{IV}=(z'x)^{-1}(z'y)$$` --- # IV - estimation (cont.) **In the general case** (more than one regressors and or instruments, `\(r\geq1\)`), the technique is **2SLS (Two Stage Least Squares)**. This approach involves the following two stages: 1. **First Stage.** Regression of the endogenous variable(s) on the instrumental variable(s) and other exogenous covariates. 2. **Second Stage.** Use the prediction values from the first stage as explanatory variables in the main regression equation. <br> To illustrate, let the structural equation be `$$y=X\beta+u=X_1\beta_1+X_2\beta_2+u$$` where `\(X_2\)` is a vector or matrix representing the endogenous variable(s) and `\(X_1\)` are exogenous covariates. The instrument are in `\(Z_2\)`. Thus, 1. The first stage would be `\(X_2=X_1\Gamma_1+Z_2\Gamma_2+\epsilon=Z\Gamma+\epsilon\)`, so one can compute `\(\hat{X}_2=Z\hat{\Gamma}\)`. 2. The second stage would be `\(y = X_1\beta_1 + \hat{X}_2\beta_2 + u\)`, hence, can get `\(\hat{\beta}\)` by (naive) OLS. --- # IV - estimation (cont.) Let's use the reduced form (the variable as function of the instruments) to get a more general expression for `\(\hat{\boldsymbol{\beta}}_{2SLS}\)`. `$$\begin{eqnarray}Y&=&X_1\beta_1+X_2\beta_2+u\\ &=&X_1\beta_1+(X_1\Gamma_1+Z_2\Gamma_2+\epsilon)\beta_2+u \\ &=&Z\Gamma\beta+\xi\\ &=&\Theta\beta+\xi \end{eqnarray}$$` where, `\(\Theta=Z\Gamma\)`, `\(\xi\)`, and `\(Z\Gamma=\left( \begin{array}{cc}I&\Gamma_1\\0&\Gamma_2\end{array} \right)\)`. Suppose `\(\Theta\)` were known (we do know `\(Z\)`, but not `\(\Gamma\)`). Then one can get `\(\beta\)` by OLS: `$$\hat{\beta}=(\Theta'\Theta)^{-1}(\Theta'Y)$$` However, by replacing `\(\Gamma\)` by the estimator `\(\hat{\Gamma}=(Z'Z)^{-1}(Z'X)\)`, we can get `\(\hat{\beta}_{2SLS}\)` as follows `$$\hat{\beta}_{2SLS} = (\hat{\Theta}'\hat{\Theta})^{-1}(\hat{\Theta}'Y)= (X'P_ZX)^{-1}X'P_ZY$$` where `\(P_Z\)` is the projection matrix `\(P_Z = Z(Z'Z)^{-1}Z'\)`. --- # The statistics when using IV 1. **Caution!** <br> Be aware of the **standard error calculation issue:** Errors from a 'manual' (naive OLS) approach in 2SLS are incorrect! <br> The OLS standard error formula assumes that `\(X_1\)` is a fixed regressor, although it is actually a prediction from the first stage and has its own sampling variability. <br> It's essential to account for this additional variability, which can be achieved through methods like - .hi-bold[Bootstrapping] - .hi-bold[Analytical corrections.] For instance, `\(V(\hat{\beta}_{IV})=\sigma^2_z\sigma^2_u/cov(z,x)=(\sigma^2/\sigma^2_x)*(1/\rho_{zx}^2)\)` . 2. **We should jointly test the instruments.** For instance, using - .hi-bold[F-test] - .hi-bold[Kleibergen-Paap rk Wald F statistic.] --- # Consistency of 2SLS **Assumption** - `\((Y_i,X_i,Z_i)\)`, `\(i=1...,n\)`, are i.i.d. - `\(\mathbb{E}(Y^2)<\infty\)` - `\(\mathbb{E}||X||^2<\infty\)` - `\(\mathbb{E}||Z||^2<\infty\)` - `\(\mathbb{E}(ZZ')\)` is positive definite - `\(\mathbb{E}(ZX')\)` has full rank - `\(\mathbb{E}(Zu)=0\)` .hi-bold[Theorem.] <br> Under these assumptions, `$$\hat{\beta}_{2SLS}\rightarrow_p\,\beta\hspace{0.6cm}\text{as}\hspace{0.6cm}n\rightarrow\infty$$` --- # Asymptotic Distribution of 2SLS **Assumption** (sufficient regularity conditions). In addition to the above mentioned assumptions, assume - `\(\mathbb{E}(Y^4)<\infty\)` - `\(\mathbb{E}||X||^4<\infty\)` - `\(\mathbb{E}||Z||^4<\infty\)` - `\(\Omega=\mathbb{E}(ZZ'u)\)` is positive definite. <br> .hi-bold[Theorem.] <br> Under the assumptions, as `\(n\rightarrow\infty\)`, `$$\sqrt{n}\left(\hat{\beta}_{2SLS}-\beta\right)\xrightarrow[d]{}N(0,V_{\beta})$$` <br> where `\(V_{\beta}=(Q_{XZ}Q_{ZZ}^{-1}Q_{ZX})^{-1}(Q_{XZ}Q_{ZZ}^{-1}\Omega Q_{ZZ}^{-1}Q_{ZX})(Q_{XZ}Q_{ZZ}^{-1}Q_{ZX})^{-1}\)` and, for instance, `\(n^{-1}X'Z\xrightarrow[]{p}Q_{XZ}=\mathbb{E}(XZ)\)`. --- # Example of IV using <i class="fab fa-r-project" role="presentation" aria-label="r-project icon"></i> .pull-left[ Let's use a dataset from Wooldridge (Wage2), which contains information on wages, schooling, among other related variables. We are interested in the returns ( `\(y=wage\)` ) to education ( `\(x=schooling\)` ). OLS with will likely be biased, `$$\begin{align} \text{Wage}_i = \beta_0 + \beta_1 \color{#6A5ACD}{\text{schooling}}_i + u_i \end{align}$$` In particular, .hi-bold[the OLS results ] <table class="table" style="margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:center;"> Variable </th> <th style="text-align:center;"> _ Coeff. _ </th> <th style="text-align:center;"> _ S.error _ </th> <th style="text-align:center;"> _ t.stat. _ </th> <th style="text-align:center;"> _ p-value _ </th> </tr> </thead> <tbody> <tr> <td style="text-align:center;background-color: white !important;"> (Intercept) </td> <td style="text-align:center;background-color: white !important;"> 176.504 </td> <td style="text-align:center;background-color: white !important;"> 89.152 </td> <td style="text-align:center;background-color: white !important;"> 1.98 </td> <td style="text-align:center;background-color: white !important;"> 0.0481 </td> </tr> <tr> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> schooling </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 58.594 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 6.439 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 9.10 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> <0.001 </td> </tr> </tbody> </table> ] .pull-right[ ```r # R code: # Select the variables to use wage_df <- wage2 %>% transmute(wage, schooling = educ, education_dad = feduc, education_mom = meduc) %>% na.omit() %>% as_tibble() head(wage_df) ## # A tibble: 6 × 4 ## wage schooling education_dad education_mom ## <int> <int> <int> <int> ## 1 769 12 8 8 ## 2 808 18 14 14 ## 3 825 14 14 14 ## 4 650 12 12 12 ## 5 562 11 11 6 ## 6 600 10 8 8 ``` ] --- # Example of IV using <i class="fab fa-r-project" role="presentation" aria-label="r-project icon"></i> (cont.) Using mother's education as an instrument. .hi-bold[Checking the instrument:] considering that `\(z\)` must (i) only affect `\(y\)` (wages) through `\(x\)` (schooling), and (ii) be uncorrelated with other factors that affect `\(y\)`, does the mother's education provide a valid instrument? .pull-left[ .hi-bold[First-stage:] The effect of `\(z\)` on `\(x\)`, `$$\begin{align} \text{Education}_i = \gamma_0 + \gamma_1 \color{#6A5ACD}{\left( \text{Mother's Education} \right)_i} + v_i \end{align}$$` <table class="table" style="margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:center;"> Variable </th> <th style="text-align:center;"> _ Coeff. _ </th> <th style="text-align:center;"> _ S.error _ </th> <th style="text-align:center;"> _ t.stat. _ </th> <th style="text-align:center;"> _ p-value _ </th> </tr> </thead> <tbody> <tr> <td style="text-align:center;background-color: white !important;"> (Intercept) </td> <td style="text-align:center;background-color: white !important;"> 10.487 </td> <td style="text-align:center;background-color: white !important;"> 0.306 </td> <td style="text-align:center;background-color: white !important;"> 34.32 </td> <td style="text-align:center;background-color: white !important;"> <0.001 </td> </tr> <tr> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> education_mom </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 0.294 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 0.027 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 10.75 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> <0.001 </td> </tr> </tbody> </table> <br> The p-value suggest the variable is an important predictor. ] .pull-right[ <img src="econometria_5_files/figure-html/first_stage_plot-1.png" width="90%" height="90%" style="display: block; margin: auto;" /> ] --- # Example of IV using <i class="fab fa-r-project" role="presentation" aria-label="r-project icon"></i> (cont.) .hi-bold[Second stage:] using `\(\hat{x}\)` from the first stage, the estimate of `\(\beta\)` in the second stage (using OLS) is: ```r # store the predicted values schooling_hat <- reg_fs$fitted.values reg_ss <- lm(wage ~ schooling_hat, wage_df) ``` <table class="table" style="font-size: 20px; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> Variable </th> <th style="text-align:right;"> Beta </th> <th style="text-align:right;"> s.e. ; </th> <th style="text-align:right;"> t.stat. </th> <th style="text-align:left;"> p-value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> Intercept </td> <td style="text-align:right;background-color: white !important;"> -501.474 </td> <td style="text-align:right;background-color: white !important;"> 244.201 </td> <td style="text-align:right;background-color: white !important;"> -2.05 </td> <td style="text-align:left;background-color: white !important;"> 0.0404 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> Schooling </td> <td style="text-align:right;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 108.214 </td> <td style="text-align:right;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 17.840 </td> <td style="text-align:right;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 6.07 </td> <td style="text-align:left;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> <0.0001 </td> </tr> </tbody> </table> <br> **Note:** <br> `\(\hat{\beta}_{1}\)` can also be computed from `\(\hat{\beta}_1=\hat{\beta}_{IV}=\hat{\phi}_1/\hat{\gamma}_1\)`, where `\(\hat{\gamma}_1\)` is computed in the first stage and `\(\phi_1\)` from `\(y_i=\phi_0+\phi_1 z+\xi\)` (reduced form). --- # Example of IV using <i class="fab fa-r-project" role="presentation" aria-label="r-project icon"></i> (cont.) In empirical works, R users rely on functions like `ivreg()` or `iv_robust()`, as they compute heteroskedasticity-robust standard errors. The former is from the `AES` package and the later from `estimatr`. The functions work quite similar to the `lm` command: `(y ~ x1 + x2 + ... | z1 + z2 + ... , data)`. Also, they compute heteroskedasticity-robust standard errors. .pull-left[ ```r # IV regression ( instrumento: educ de la madre) #iv_est <- iv_robust(wage ~ schooling | education_mom, data = wage_df) iv_est <- ivreg(wage ~ schooling | education_mom, data = wage_df) ``` ] .pull-right[ <table class="table" style="margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:center;"> Variable </th> <th style="text-align:center;"> _ Coeff. _ </th> <th style="text-align:center;"> _ S.error _ </th> <th style="text-align:center;"> _ t.stat. _ </th> <th style="text-align:center;"> _ p-value _ </th> </tr> </thead> <tbody> <tr> <td style="text-align:center;background-color: white !important;"> (Intercept) </td> <td style="text-align:center;background-color: white !important;"> -501.474 </td> <td style="text-align:center;background-color: white !important;"> 246.684 </td> <td style="text-align:center;background-color: white !important;"> -2.03 </td> <td style="text-align:center;background-color: white !important;"> 0.0424 </td> </tr> <tr> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> schooling </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 108.214 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 18.021 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 6.00 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> <0.001 </td> </tr> </tbody> </table> ] Or using the mother's and father's education as instruments: .pull-left[ ```r # IV regression (usando ivreg y dos instrumentos) ivreg(wage ~ schooling | education_mom + education_dad, data = wage_df) ``` ] .pull-right[ <table class="table" style="margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:center;"> Variable </th> <th style="text-align:center;"> _ Coeff. _ </th> <th style="text-align:center;"> _ S.error _ </th> <th style="text-align:center;"> _ t.stat. _ </th> <th style="text-align:center;"> _ p-value _ </th> </tr> </thead> <tbody> <tr> <td style="text-align:center;background-color: white !important;"> (Intercept) </td> <td style="text-align:center;background-color: white !important;"> -454.683 </td> <td style="text-align:center;background-color: white !important;"> 201.201 </td> <td style="text-align:center;background-color: white !important;"> -2.26 </td> <td style="text-align:center;background-color: white !important;"> 0.0241 </td> </tr> <tr> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> schooling </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 104.789 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 14.685 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> 7.14 </td> <td style="text-align:center;background-color: white !important;font-weight: bold;color: #6A5ACD !important;"> <0.001 </td> </tr> </tbody> </table> ] --- # Example of IV using Stata Or in `Stata` it would be `ivreg y (x = z1 z2 ...) , r` .center[ ] --- https://github.com/edrubin/EC421S19/blob/master/LectureNotes/11InstrumentalVariables/11_instrumental_variables_NoPause.Rmd # Cierre </br></br></br> ## <center>¿Preguntas?</center> .center[ ] `$$\,$$` .center[O vía E-mail: [lchanci1@binghamton.edu](mailto:lchanci1@binghamton.edu)]